
尽管采用 acks = all 但是也会出现 不一致的场景,例如:
假设 leader 接受了 producer 传来的数据为 8 条,ISR 中三台 follower(broker0,broker1,broker2)开始同步数据,由于网络传输,另外两台 follower 同步数据的速率不同。当 broker1 同步了 4 条数据,broker2 已经同步了 6 条数据,此时,leader-broker0 突然挂掉,从 ISR 中选取了 broker1 作为主节点,此时 leader-broker1 同步了 4 条,broker2 同步 6,就会造成 leader 和 followe r之间数据不一致问题。

- HW (High Watermark)俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息,对于同一个副本对象而言,其 HW 值不会大于 LEO 值。小于等于 HW 值的所有消息都被认为是“已备份”的(replicated) 。所有分区副本中消息偏移量最小值。
- LEO(Log End Offset),即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果 LEO =8,那么表示该副本保存了 8 条消息,位移值范围是[0, 7]。LEO 的大小相当于当前日志分区中最后一条消息的 offset 值加1,分区 ISR 集合中的每个副本都会维护自身的 LEO,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
针对不同的产生原因,解决方案不同:
- 当服务出现故障时:如果是 Follower 发生故障,这不会影响消息写入,只不过是少了一个备份而已。处理 相对简单一点。Kafka 会做如下处理:
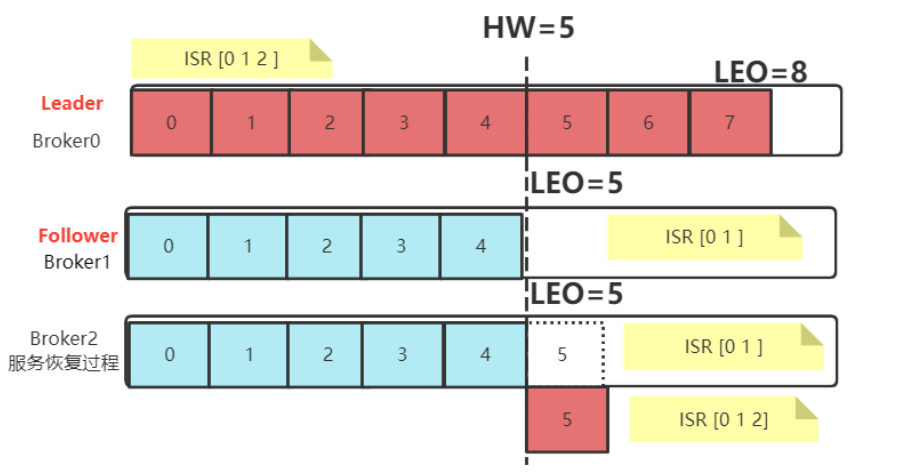
-
- 将故障的 Follower 节点临时踢出 ISR 集合。而其他 Leader 和 Follower 继续正常接收消息。
- 出现故障的 Follower 节点恢复后,不会立即加入 ISR 集合。该 Follower 节点会读取本地记录的上一次的 HW,将自己的日志中高于 HW 的部分信息全部删除掉,然后从 HW 开始,向 Leader 进行消息同步。
- 等到该 Follower 的 LEO 大于等于整个 Partiton 的 HW 后,就重新加入到 ISR 集合中。这也就是说这个 Follower 的消息进度追上了 Leader。
- 如果是 Leader 节点出现故障,Kafka 为了保证消息的一致性,处理就会相对复杂一点。

-
- Leader 发生故障,会从 ISR 中进行选举,将一个原本是 Follower 的 Partition提升为新的 Leader。这时, 消息有可能没有完成同步,所以新的 Leader 的LEO 会低于之前 Leader 的 LEO。
- Kafka 中的消息都只能以 Leader 中的备份为准。其他 Follower 会将各自的Log 文件中高于 HW 的部分全部 清理掉,然后从新的 Leader 中同步数据。
- 旧的 Leader 恢复后,将作为 Follower 节点,进行数据恢复。


